
Call Packages
packages = c('mice', 'dplyr', 'foreign', 'finalfit', 'haven')
for (package in packages){
if(!require(package, character.only = T)){
install.packages(package)
library(package, character.only = T)
}
}
## Loading required package: mice
##
## Attaching package: 'mice'
## The following object is masked from 'package:stats':
##
## filter
## The following objects are masked from 'package:base':
##
## cbind, rbind
## Loading required package: dplyr
##
## Attaching package: 'dplyr'
## The following objects are masked from 'package:stats':
##
## filter, lag
## The following objects are masked from 'package:base':
##
## intersect, setdiff, setequal, union
## Loading required package: foreign
## Loading required package: finalfit
## Loading required package: haven
Load Data
df = read.spss('COVID_demo_supp_acEng.sav', to.data.frame = T)
df$edu = as.ordered(df$edu)
str(df)
## 'data.frame': 1903 obs. of 25 variables:
## $ ID : num 1 2 3 4 5 6 7 8 9 10 ...
## $ age : num 21 19 20 19 26 24 19 21 19 18 ...
## $ gender : Factor w/ 3 levels "M","F","Unsure": 3 2 1 2 2 2 2 1 1 2 ...
## $ race : Factor w/ 6 levels "White","Black",..: 6 2 4 1 1 1 1 6 1 1 ...
## $ hispanic : Factor w/ 2 levels "0","1": 2 1 1 1 1 1 2 1 1 1 ...
## $ edu : Ord.factor w/ 5 levels "2"<"3"<"4"<"5"<..: 3 2 3 3 4 4 3 3 2 2 ...
## $ liveAlone : Factor w/ 2 levels "0","1": NA NA 1 1 2 1 2 1 1 1 ...
## $ dept : num 1 5 7 5 7 5 3 5 6 5 ...
## $ admin : num 3 5 7 5 3 4 3 3 6 4 ...
## $ students : num 2 5 7 5 5 7 6 7 6 6 ...
## $ parents : num 2 7 7 7 7 7 6 7 6 7 ...
## $ family : num 3 7 7 7 7 7 7 7 6 7 ...
## $ relatives : num 2 6 7 7 7 7 5 7 6 7 ...
## $ partner : num 2 NA NA 7 NA 7 NA 2 NA 7 ...
## $ friends : num 3 7 7 7 5 7 6 7 6 7 ...
## $ masterSkills : num NA 2 6 NA 2 4 2 4 3 3 ...
## $ doDifficultTasks : num NA 2 6 NA 2 4 2 2 3 3 ...
## $ completeClassWork: num NA 3 6 NA 2 4 3 4 4 5 ...
## $ learnHardWork : num NA 3 6 NA 2 4 2 4 4 5 ...
## $ doHardestWork : num NA 3 6 NA 2 4 2 1 3 3 ...
## $ doWellInClass : num NA 3 6 NA 2 4 1 4 4 4 ...
## $ meetGoals : num NA 5 6 NA 2 3 2 3 4 4 ...
## $ findJob : num NA 5 6 NA 1 2 2 6 2 3 ...
## $ getIntoGradSchool: num NA 4 6 NA 1 2 3 6 2 5 ...
## $ dep : num 4 2 1 2 4 2 2 2 2 2 ...
## - attr(*, "codepage")= int 65001
Missing Pattern Analysis
Check missingness
df %>%
select('age', 'dept','admin', 'students') %>% #Select a few items as an example
ff_glimpse()
## $Continuous
## label var_type n missing_n missing_percent mean sd min
## age age <dbl> 1877 26 1.4 22.5 4.9 17.0
## dept dept <dbl> 1376 527 27.7 5.0 1.8 1.0
## admin admin <dbl> 1401 502 26.4 3.9 1.8 1.0
## students students <dbl> 1413 490 25.7 5.4 1.5 1.0
## quartile_25 median quartile_75 max
## age 19.0 21.0 24.0 63.0
## dept 4.0 5.0 7.0 7.0
## admin 3.0 4.0 5.0 7.0
## students 4.0 6.0 7.0 7.0
##
## $Categorical
## data frame with 0 columns and 1903 rows
##
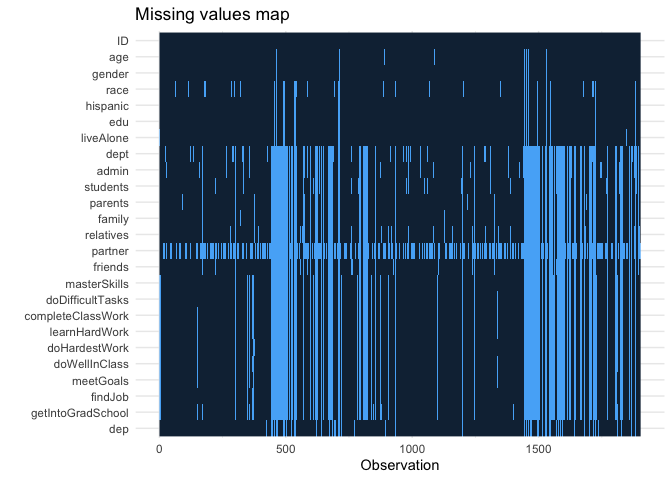
Missing pattern by ID
df %>%
missing_plot()
Missing pattern by variable
explanatory = colnames(df)[2:7] #Demographic variables
dependent = 'dep'
df %>%
missing_pattern(dependent, explanatory)
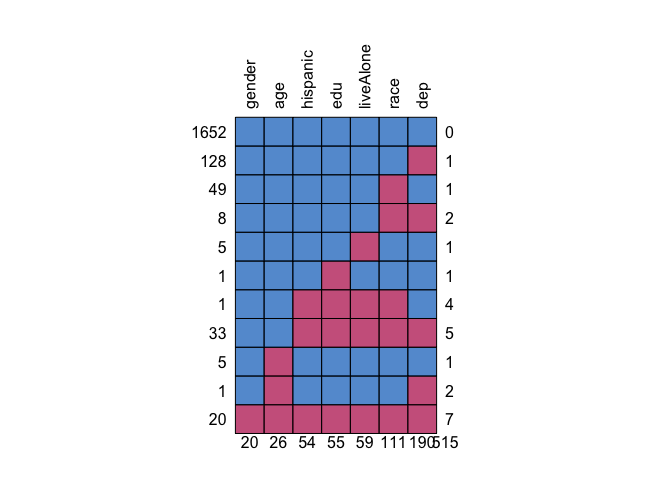
## gender age hispanic edu liveAlone race dep
## 1652 1 1 1 1 1 1 1 0
## 128 1 1 1 1 1 1 0 1
## 49 1 1 1 1 1 0 1 1
## 8 1 1 1 1 1 0 0 2
## 5 1 1 1 1 0 1 1 1
## 1 1 1 1 0 1 1 1 1
## 1 1 1 0 0 0 0 1 4
## 33 1 1 0 0 0 0 0 5
## 5 1 0 1 1 1 1 1 1
## 1 1 0 1 1 1 1 0 2
## 20 0 0 0 0 0 0 0 7
## 20 26 54 55 59 111 190 515
Compare depedent variable scores by explanaotry variable group
df %>%
summary_factorlist(dependent, explanatory, na_include=TRUE, p=TRUE)
## Note: dependent includes missing data. These are dropped.
## label levels unit value p
## age [17.0,63.0] Mean (sd) 2.1 (0.8) 0.006
## gender M Mean (sd) 1.9 (0.8) <0.001
## F Mean (sd) 2.2 (0.8)
## Unsure Mean (sd) 2.4 (0.9)
## race White Mean (sd) 2.2 (0.8) <0.001
## Black Mean (sd) 2.3 (1.0)
## IAI/AN Mean (sd) 2.3 (1.0)
## Asian Mean (sd) 2.0 (0.8)
## NH/OPI Mean (sd) 2.2 (1.5)
## Multiple Mean (sd) 2.3 (0.9)
## (Missing) Mean (sd) 2.0 (0.8)
## hispanic 0 Mean (sd) 2.1 (0.8) 0.001
## 1 Mean (sd) 2.3 (0.9)
## edu 2 Mean (sd) 2.0 (0.7) 0.001
## 3 Mean (sd) 2.0 (0.8)
## 4 Mean (sd) 2.2 (0.9)
## 5 Mean (sd) 2.0 (0.8)
## 6 Mean (sd) 2.0 (0.8)
## (Missing) Mean (sd) 2.0 (1.4)
## liveAlone 0 Mean (sd) 2.1 (0.8) 0.491
## 1 Mean (sd) 2.1 (0.9)
## (Missing) Mean (sd) 2.2 (1.2)
Compare mssing patterns of dependent variable by explanatory variable
df %>%
missing_pairs(dependent, explanatory,
position = "fill") #Use position = fill to compare missing proportions #Use proportion = stack to do raw comparisons
## Registered S3 method overwritten by 'GGally':
## method from
## +.gg ggplot2
## Warning: Removed 190 rows containing non-finite values (stat_boxplot).
## Warning: Removed 26 rows containing non-finite values (stat_boxplot).
## Warning: Removed 190 rows containing non-finite values (stat_boxplot).
## Warning: Removed 26 rows containing non-finite values (stat_boxplot).
## Warning: Removed 190 rows containing non-finite values (stat_boxplot).
## Warning: Removed 26 rows containing non-finite values (stat_boxplot).
## Warning: Removed 190 rows containing non-finite values (stat_boxplot).
## Warning: Removed 26 rows containing non-finite values (stat_boxplot).
## Warning: Removed 190 rows containing non-finite values (stat_boxplot).
## Warning: Removed 26 rows containing non-finite values (stat_boxplot).
## Warning: Removed 190 rows containing non-finite values (stat_boxplot).
## Warning: Removed 26 rows containing non-finite values (stat_boxplot).
## Warning: Removed 190 rows containing non-finite values (stat_boxplot).
## Warning: Removed 26 rows containing non-finite values (stat_boxplot).
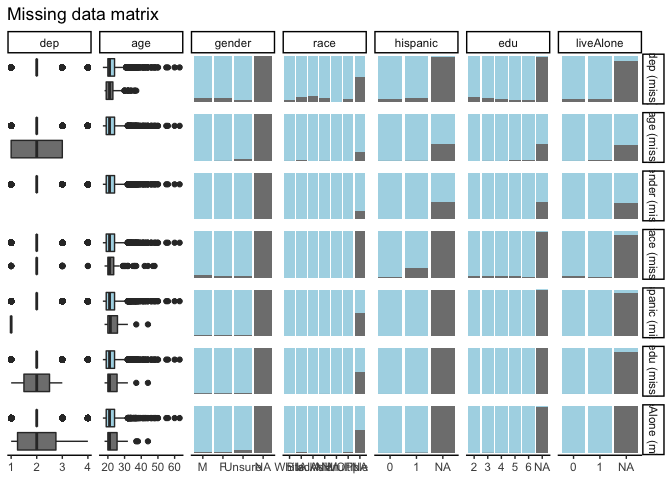
Quantify the missing patterns of dependent variable based on explanatory variables
df %>%
missing_compare(dependent, explanatory) %>%
knitr::kable(row.names=FALSE, align = c("l", "l", "r", "r", "r"))
## Warning in chisq.test(gender, dep): Chi-squared approximation may be incorrect
## Warning in chisq.test(race, dep): Chi-squared approximation may be incorrect
## Warning in chisq.test(edu, dep): Chi-squared approximation may be incorrect
| Missing data analysis: dep | Not missing | Missing | p | |
|---|---|---|---|---|
| age | Mean (SD) | 22.5 (5.0) | 22.1 (4.2) | 0.302 |
| gender | M | 486 (90.8) | 49 (9.2) | 0.739 |
| F | 1192 (90.9) | 119 (9.1) | ||
| Unsure | 35 (94.6) | 2 (5.4) | ||
| race | White | 894 (94.9) | 48 (5.1) | 0.009 |
| Black | 71 (87.7) | 10 (12.3) | ||
| IAI/AN | 7 (87.5) | 1 (12.5) | ||
| Asian | 603 (90.5) | 63 (9.5) | ||
| NH/OPI | 4 (100.0) | 0 (0.0) | ||
| Multiple | 84 (92.3) | 7 (7.7) | ||
| hispanic | 0 | 1507 (92.7) | 118 (7.3) | 0.605 |
| 1 | 205 (91.5) | 19 (8.5) | ||
| edu | 2 | 23 (88.5) | 3 (11.5) | 0.299 |
| 3 | 330 (90.7) | 34 (9.3) | ||
| 4 | 835 (92.5) | 68 (7.5) | ||
| 5 | 414 (94.1) | 26 (5.9) | ||
| 6 | 109 (94.8) | 6 (5.2) | ||
| liveAlone | 0 | 1583 (92.6) | 127 (7.4) | 1.000 |
| 1 | 124 (92.5) | 10 (7.5) |
Multivariate Imputation by Chained Equations (MICE)
set.seed(5)
df_imp = mice(df[,-c(1,5)], m = 5, maxit = 30, printFlag = F)
#Hispanic var (var 5) tends to not converge -> How would you deal with this issue instead of removing the var?
Imputed Results
df_imp
## Class: mids
## Number of multiple imputations: 5
## Imputation methods:
## age gender race edu
## "pmm" "polyreg" "polyreg" "polr"
## liveAlone dept admin students
## "logreg" "pmm" "pmm" "pmm"
## parents family relatives partner
## "pmm" "pmm" "pmm" "pmm"
## friends masterSkills doDifficultTasks completeClassWork
## "pmm" "pmm" "pmm" "pmm"
## learnHardWork doHardestWork doWellInClass meetGoals
## "pmm" "pmm" "pmm" "pmm"
## findJob getIntoGradSchool dep
## "pmm" "pmm" "pmm"
## PredictorMatrix:
## age gender race edu liveAlone dept admin students parents family
## age 0 1 1 1 1 1 1 1 1 1
## gender 1 0 1 1 1 1 1 1 1 1
## race 1 1 0 1 1 1 1 1 1 1
## edu 1 1 1 0 1 1 1 1 1 1
## liveAlone 1 1 1 1 0 1 1 1 1 1
## dept 1 1 1 1 1 0 1 1 1 1
## relatives partner friends masterSkills doDifficultTasks
## age 1 1 1 1 1
## gender 1 1 1 1 1
## race 1 1 1 1 1
## edu 1 1 1 1 1
## liveAlone 1 1 1 1 1
## dept 1 1 1 1 1
## completeClassWork learnHardWork doHardestWork doWellInClass meetGoals
## age 1 1 1 1 1
## gender 1 1 1 1 1
## race 1 1 1 1 1
## edu 1 1 1 1 1
## liveAlone 1 1 1 1 1
## dept 1 1 1 1 1
## findJob getIntoGradSchool dep
## age 1 1 1
## gender 1 1 1
## race 1 1 1
## edu 1 1 1
## liveAlone 1 1 1
## dept 1 1 1
Run analysis on each imputed dataset and pool the results
myFormula = formula(paste(dependent, '~', paste(colnames(df)[-c(1,5, 25, 26)], collapse = ' + ')))
#Because of the way the ```with``` function is written, I cannot directly parse myFormula to the lm function.
#As lazy as I am, I decided to print out myFormula and copy the words to the following code.
fit_dep = with(df_imp,
lm(dep ~ age + gender + race + edu + liveAlone + dept + admin +
students + parents + family + relatives + partner + friends +
masterSkills + doDifficultTasks + completeClassWork + learnHardWork +
doHardestWork + doWellInClass + meetGoals + findJob + getIntoGradSchool))
result_dep = round(summary(pool(fit_dep))[,-1], 3)
row.names(result_dep) = summary(pool(fit_dep))[,1]
result_dep
## estimate std.error statistic df p.value
## (Intercept) 3.473 0.180 19.309 167.788 0.000
## age -0.003 0.005 -0.656 754.637 0.512
## genderF 0.161 0.046 3.466 50.111 0.001
## genderUnsure 0.381 0.143 2.653 82.571 0.010
## raceBlack 0.151 0.096 1.581 99.507 0.117
## raceIAI/AN 0.111 0.284 0.391 130.153 0.697
## raceAsian -0.233 0.044 -5.349 119.662 0.000
## raceNH/OPI 0.250 0.372 0.673 1740.862 0.501
## raceMultiple -0.022 0.085 -0.265 357.516 0.791
## edu.L 0.085 0.138 0.617 32.627 0.541
## edu.Q -0.018 0.101 -0.173 101.069 0.863
## edu.C 0.000 0.080 0.003 22.909 0.998
## edu^4 0.017 0.041 0.400 93.268 0.690
## liveAlone1 0.125 0.074 1.682 137.669 0.095
## dept 0.000 0.017 -0.025 20.197 0.980
## admin -0.018 0.014 -1.277 61.085 0.206
## students 0.039 0.019 2.033 14.916 0.060
## parents -0.041 0.034 -1.190 13.072 0.255
## family -0.048 0.029 -1.667 41.559 0.103
## relatives -0.014 0.023 -0.598 21.149 0.556
## partner -0.001 0.020 -0.074 13.503 0.942
## friends -0.011 0.020 -0.544 33.637 0.590
## masterSkills 0.000 0.025 -0.002 60.658 0.999
## doDifficultTasks -0.053 0.024 -2.219 254.749 0.027
## completeClassWork -0.021 0.026 -0.811 145.970 0.419
## learnHardWork 0.013 0.039 0.332 15.337 0.744
## doHardestWork -0.003 0.031 -0.085 39.464 0.933
## doWellInClass -0.057 0.030 -1.947 43.639 0.058
## meetGoals -0.062 0.024 -2.619 147.913 0.010
## findJob -0.026 0.022 -1.174 43.184 0.247
## getIntoGradSchool -0.014 0.022 -0.655 59.409 0.515
See https://bookdown.org/mwheymans/bookmi/rubins-rules.html#degrees-of-freedom-and-p-values for how to calculate residual degrees of freedom for hypothesis testing
Prep imputed data for alternative uses
####(This is not the ideal way using mulple imputation.)
data_imp_long = complete(df_imp, action = 'long', include = F)
calculate_mode = function(x) {
uniqx = unique(na.omit(x))
uniqx[which.max(tabulate(match(x, uniqx)))]
}
data_imp_factorSum =
data_imp_long %>%
group_by(.id) %>%
summarise_if(is.factor, calculate_mode)
data_imp_numericSum =
data_imp_long %>%
group_by(.id) %>%
summarise_if(is.numeric, median)
data_imp_summary = merge(data_imp_factorSum, data_imp_numericSum, by = '.id')
colnames(data_imp_summary)[1] = 'id'
data_imp_summary$.imp = NULL
str(data_imp_summary)
## 'data.frame': 1903 obs. of 24 variables:
## $ id : int 1 2 3 4 5 6 7 8 9 10 ...
## $ gender : Factor w/ 3 levels "M","F","Unsure": 3 2 1 2 2 2 2 1 1 2 ...
## $ race : Factor w/ 6 levels "White","Black",..: 6 2 4 1 1 1 1 6 1 1 ...
## $ edu : Ord.factor w/ 5 levels "2"<"3"<"4"<"5"<..: 3 2 3 3 4 4 3 3 2 2 ...
## $ liveAlone : Factor w/ 2 levels "0","1": 1 1 1 1 2 1 2 1 1 1 ...
## $ age : num 21 19 20 19 26 24 19 21 19 18 ...
## $ dept : num 1 5 7 5 7 5 3 5 6 5 ...
## $ admin : num 3 5 7 5 3 4 3 3 6 4 ...
## $ students : num 2 5 7 5 5 7 6 7 6 6 ...
## $ parents : num 2 7 7 7 7 7 6 7 6 7 ...
## $ family : num 3 7 7 7 7 7 7 7 6 7 ...
## $ relatives : num 2 6 7 7 7 7 5 7 6 7 ...
## $ partner : num 2 7 7 7 4 7 5 2 6 7 ...
## $ friends : num 3 7 7 7 5 7 6 7 6 7 ...
## $ masterSkills : num 2 2 6 4 2 4 2 4 3 3 ...
## $ doDifficultTasks : num 2 2 6 3 2 4 2 2 3 3 ...
## $ completeClassWork: num 1 3 6 4 2 4 3 4 4 5 ...
## $ learnHardWork : num 2 3 6 4 2 4 2 4 4 5 ...
## $ doHardestWork : num 1 3 6 4 2 4 2 1 3 3 ...
## $ doWellInClass : num 1 3 6 4 2 4 1 4 4 4 ...
## $ meetGoals : num 1 5 6 4 2 3 2 3 4 4 ...
## $ findJob : num 3 5 6 4 1 2 2 6 2 3 ...
## $ getIntoGradSchool: num 3 4 6 3 1 2 3 6 2 5 ...
## $ dep : num 4 2 1 2 4 2 2 2 2 2 ...
write_sav(data_imp_summary, 'COVID_demo_supp_acEng_imp.sav')